A Deep Dive into Generative Modeling
Generative modeling has faced a fair amount of scrutiny since its inception, particularly due to the use of unlicensed training data. Through our collaboration with Soundly—the world-leading sound effects platform—we at HANCE are in a unique position to ethically train similar models in the audio realm.

Our Vision
Generative audio modeling is an exciting field, and the implications of having well-performing models by our fingertips are many. Sound designers will spend less time gathering sources for unique and memorable designs. Multimedia proof of concepts will be easier to produce. Digital hiccups while recording music will be fixed in seconds. Production quality won’t have to be sacrificed for speed under the threat of looming deadlines. New methods for musical expression can be discovered.
Impressive advances are made every year. To keep up to date with recent advances, researchers at HANCE have experimented with models like AudioGEN, AudioLDM, RAVE, and more to establish an understanding of what already exists. Today we are laying the foundations for our own contributions to this field.
Exploring the Dataset
As with any data science project, the first step is to chart the data. As Soundly serves a community of sound designers, the frequency ratio between sound classes is bound to be skewed towards their needs. As such, augmentation methods must be applied to ensure our models can describe each class equally well.
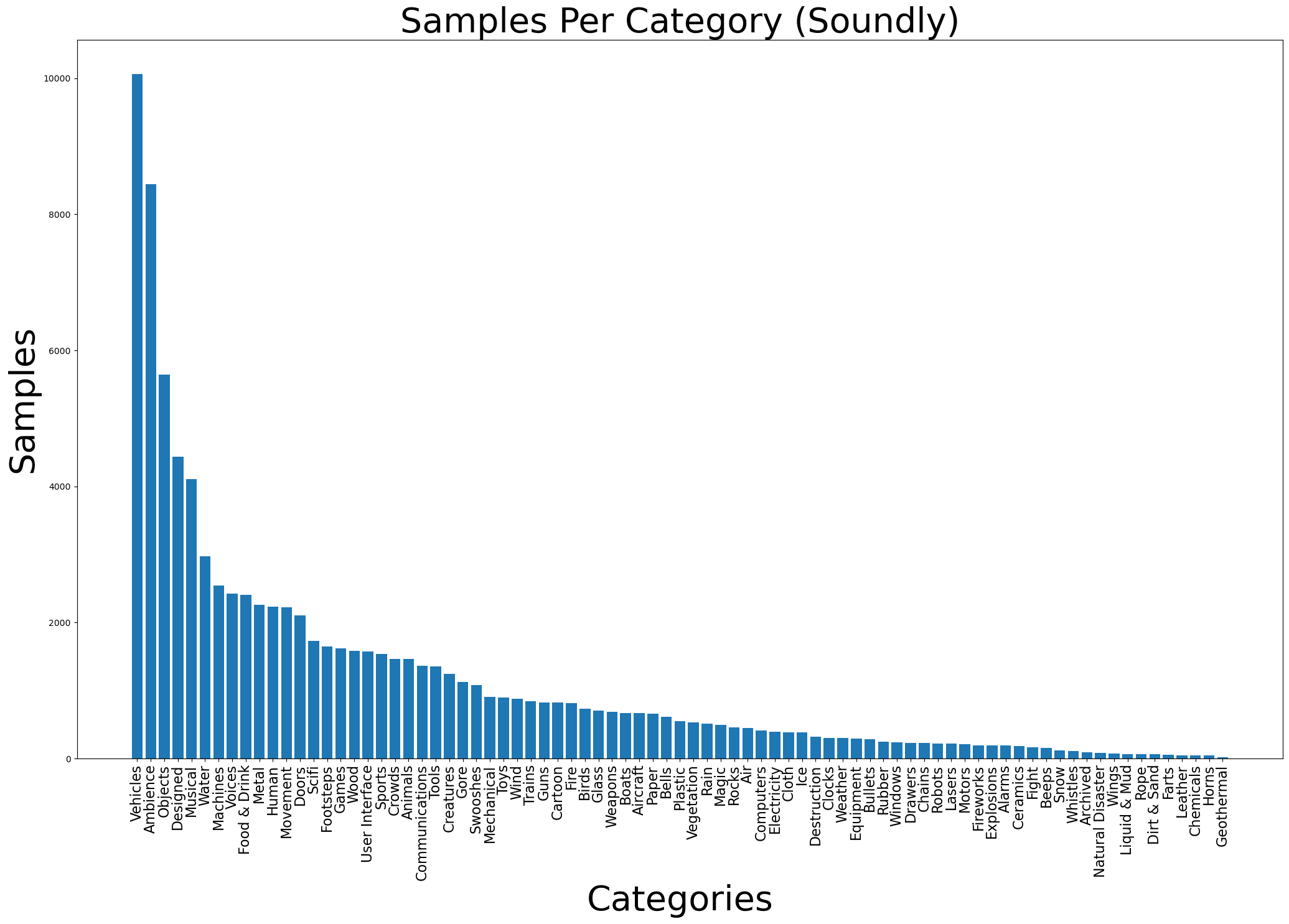
Upon closer inspection, the Soundly library comprises 3 kinds of sounds:
- Continuous: This is mostly the case for ambiences and music
- One-shot: a single sound in a single file
- Few-shot: multiple sounds with a clear start and end time in the same file
The Soundly dataset is growing steadily, and has surpassed 100,000 sound files since the original charting of the data, all with descriptive names and categorized using the Universal Category System (UCS). Even so, 100,000 sounds is comparatively low considering state-of-the-art models which utilize datasets of over 600,000 individual files.
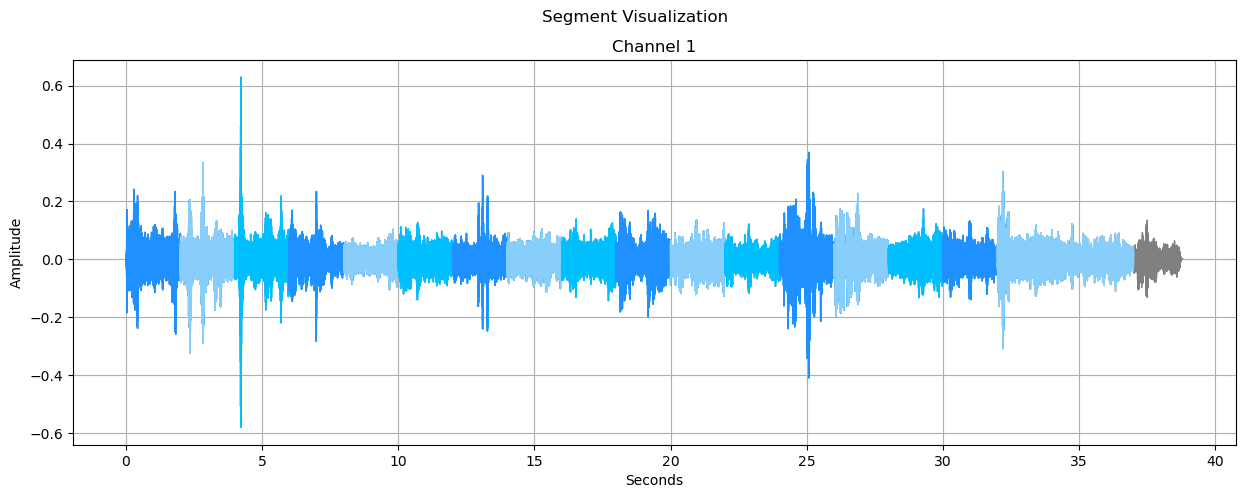
There are numerous ways to ensure we get as much mileage out of our data as possible. Text descriptions can be augmented using existing language models. Audio can be segmented into smaller files to get more data out of few-shot and continuous sounds, one-shots can be padded to improve translation invariance along the time axis, pitch and time stretching algorithms can be used for further augmentation.
At HANCE, we believe that the creative works of others should not be exploited for personal gain. That is why we work with open source datasets to further augment our training data, and help our clients create smarter solutions.
Choice of Architecture
Various neural network architectures have been proposed for similar tasks, each with their own benefits and drawbacks. Variational Autoencoders (VAEs) are known for their ability to reconstruct input data, and the ability to sample new, albeit noisy, data from a learned distribution. Latent Diffusion allows conditioning inputs such as text to drive the generation process, but can be relatively slow due to the denoising process. Flow-based methods are fast, but their range of expression is limited. Generative Adversarial Networks (GANs) achieve superb quality, but are notoriously difficult to train due to issues like mode collapse, where the model is unable to explore all corners of the training set distribution.
Methods exist to handle some of these issues, with varying degrees of complexity and success, including different loss functions and network layers. Some solutions have even been developed by combining architectures, for example by freezing the encoder weights in a VAE after a normally distributed latent space has been found, before fine-tuning the model using a GAN to mitigate the blurry effect. However, despite rapid advancements, such models cannot yet compare with the production value sought after by audio professionals. Through our extensive network of renowned sound artists and producers, HANCE receives direct and valuable feedback from trained ears all over the world to aid us on our mission.
On the User Experience
As you can imagine, there are countless avenues to explore for interacting with trained generative models, each with their own UX-considerations. Generative models from other domains often rely on crossing natural language with domain specific data to create an encoding useful in the generation process, something users have come to expect. This allows a great deal of control over the output.
On the other hand, training models on natural language may also embed human bias into the models, causing undesirable long term effects. Researchers at HANCE propose solutions with such issues in mind. Since our data is structured based on UCS, a potential solution is to treat each sub-category as a prompt for sound generation, bypassing natural language bias altogether, while the user retains sufficient amounts of control through a system they are familiar with. Other solutions may include selective partnerships with data service providers and developers.
Moving away from text altogether, samples may be generated in isolation or based on surrounding content by the click of a single button if the lack of direct control over the sample is not an issue. This can be the case for a model designed to only generate a single class of audio. More elaborate graphical user interfaces could prove useful in other scenarios. For example, an interactive X-Y-plot for exploring the latent space produced by a VAE. One needs to consider both the context in which such models will be used and the amount of control desired by the end user to find lasting solutions to these problems.
Our Next Steps
The HANCE team is excited to use what we have learned over the past few years to take a deep dive into generative modeling. We continue to learn, we continue to grow, and we will continue to use our knowledge and resources to assist our clients with the creation of cutting edge products for the world of tomorrow.