Mind the gaps – reducing artifacts in compressed audio
Most of us are familiar with the unpleasant artifacts in audio suffering from too aggressive bit rate reduction. Not only is high-frequency content lost, but randomly occurring gaps in the frequency spectrum cause a distinctive artificial sound.

The most widely known audio compression algorithm is probably MPEG Layer 3, usually referred to as simply MP3. The spectrograms below show the effect of heavy compression on a voice recording.
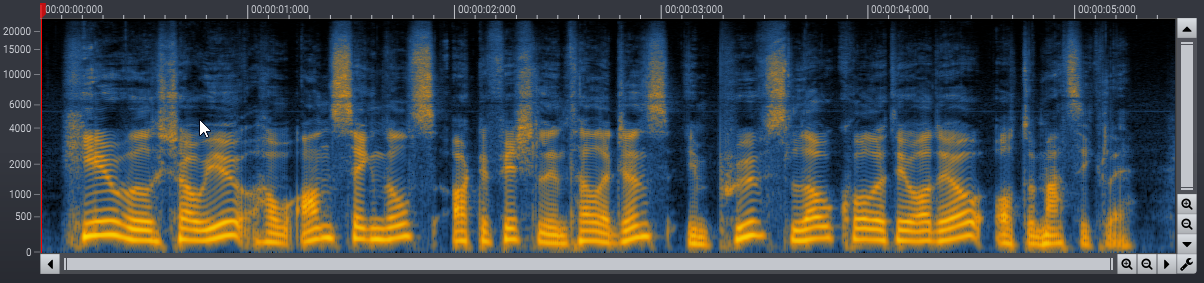
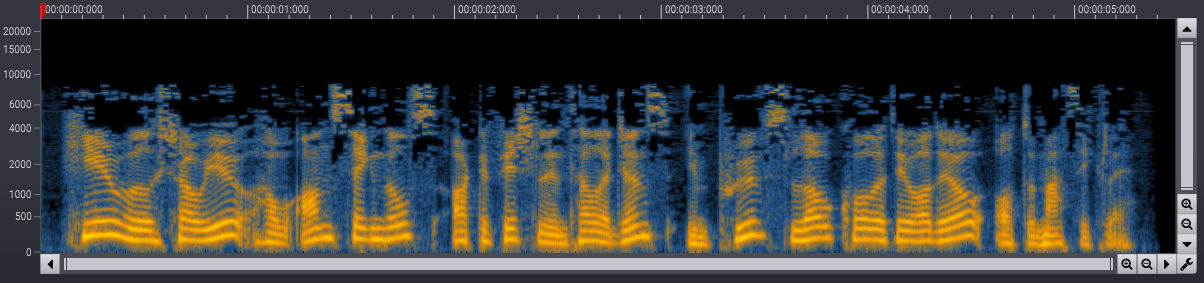
Using deep learning to recover magnitude spectrograms
We wanted to explore if we can reduce the artifacts by training a neural network to fill in the missing content. In source separation, we typically estimate a mask multiplied by the input spectrogram magnitudes to create the output spectrogram. The neural network will generally perform better when estimating a mask rather than the output magnitudes directly. When recovering compressed audio, however, we need to fill gaps in the magnitude spectrogram. The magnitudes of the time-frequency components within the gap are typically zero, so multiplying with a mask will not make it possible to recover these components. We, therefore, have to train our network to estimate the spectrogram magnitudes directly.
Recovering the magnitude spectrogram
We created a training set consisting of a mixture of dialogue recordings and music. Then we encoded the complete training set using MP3 at 32 kbit/s. We used a four-layered convolutional neural network with U-Net topology, and some custom layers to estimate the uncompressed magnitude spectrogram using the magnitude spectrogram of the compressed audio as input. The absolute difference between the magnitude spectrogram of the uncompressed audio and estimated the magnitude spectrogram served as a loss function (L1 norm).
Dealing with phase
Since the network only estimated the absolute magnitude spectrogram, we needed to predict the time-frequency components’ phase somehow. We did not attempt to estimate the phase with a neural network, but used a proprietary method to estimate phase based on surrounding frequency components.
Results and conclusion
We found that convolutional networks can be very capable of filling in gaps in the magnitude spectrogram. Figure 2 shows the magnitude spectrogram after recovering the compressed audio from Figure 1b.
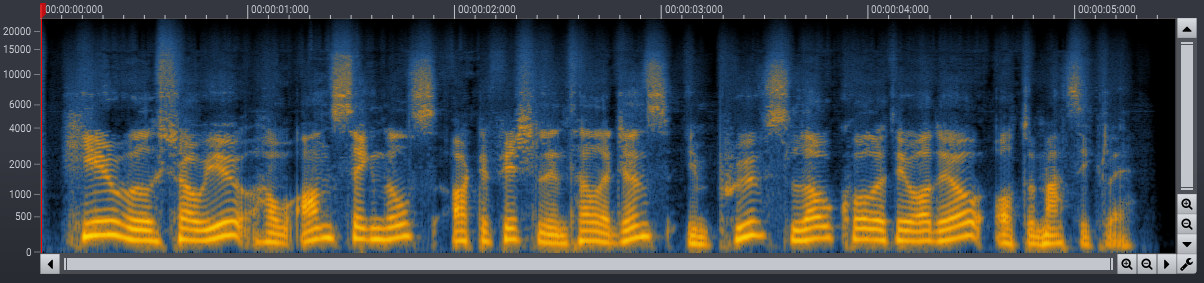
We also found that phase estimation plays an important role, but a computationally effective post-processing step is sufficient to achieve good results.
Before and after the spectral recovery process. Please use the switch in the player to toggle the processing on and off.